publications
2025
October
- PloS one
 Challenges in explaining deep learning models for data with biological variationLenka Tětková, Erik Schou Dreier, Robin Malm, and Lars Kai HansenPloS one, Oct 2025
Challenges in explaining deep learning models for data with biological variationLenka Tětková, Erik Schou Dreier, Robin Malm, and Lars Kai HansenPloS one, Oct 2025Much machine learning research progress is based on developing models and evaluating them on a benchmark dataset (e.g., ImageNet for images). However, applying such benchmark-successful methods to real-world data often does not work as expected. This is particularly the case for biological data where we expect variability at multiple time and spatial scales. Typical benchmark data has simple, dominant semantics, such as a number, an object type, or a word. In contrast, biological samples often have multiple semantic components leading to complex and entangled signals. Complexity is added if the signal of interest is related to atypical states, e.g., disease, and if there is limited data available for learning. In this work, we focus on image classification of real-world biological data that are, indeed, different from standard images. We are using grain data and the goal is to detect diseases and damages, for example, “pink fusarium" and “skinned". Pink fusarium, skinned grains, and other diseases and damages are key factors in setting the price of grains or excluding dangerous grains from food production. Apart from challenges stemming from differences of the data from the standard toy datasets, we also present challenges that need to be overcome when explaining deep learning models. For example, explainability methods have many hyperparameters that can give different results, and the ones published in the papers do not work on dissimilar images. Other challenges are more general: problems with visualization of the explanations and their comparison since the magnitudes of their values differ from method to method. An open fundamental question also is: How to evaluate explanations? It is a non-trivial task because the “ground truth" is usually missing or ill-defined. Also, human annotators may create what they think is an explanation of the task at hand, yet the machine learning model might solve it in a different and perhaps counter-intuitive way. We discuss several of these challenges and evaluate various post-hoc explainability methods on grain data. We focus on robustness, quality of explanations, and similarity to particular “ground truth" annotations made by experts. The goal is to find the methods that overall perform well and could be used in this challenging task. We hope that the proposed pipeline would be used as a framework for evaluating explainability methods in specific use cases.
September
- Preprint
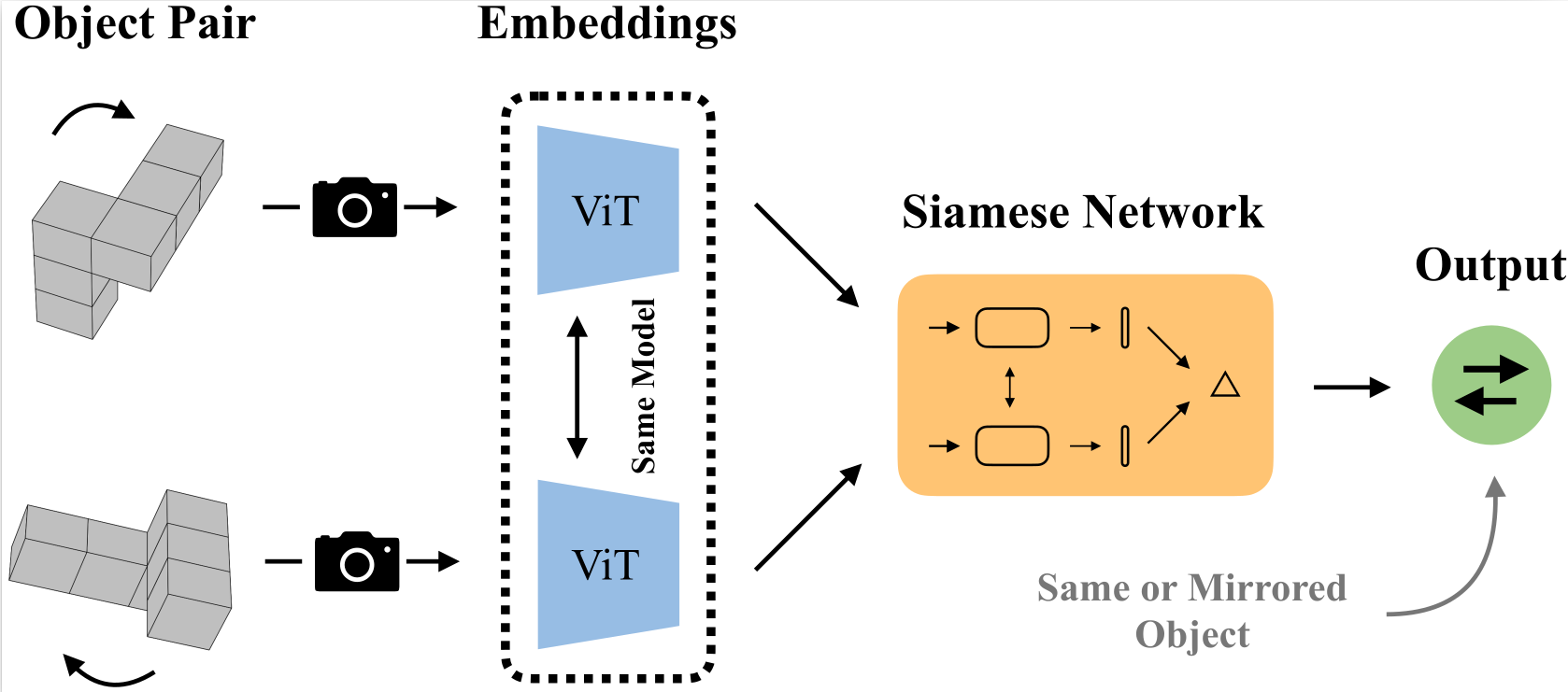 Large Vision Models Can Solve Mental Rotation ProblemsSebastian Ray Mason, Anders Gjølbye, Phillip Chavarria Højbjerg, Lenka Tětková, and Lars Kai HansenarXiv preprint arXiv:2509.15271, Sep 2025
Large Vision Models Can Solve Mental Rotation ProblemsSebastian Ray Mason, Anders Gjølbye, Phillip Chavarria Højbjerg, Lenka Tětková, and Lars Kai HansenarXiv preprint arXiv:2509.15271, Sep 2025Mental rotation is a key test of spatial reasoning in humans and has been central to understanding how perception supports cognition. Despite the success of modern vision transformers, it is still unclear how well these models develop similar abilities. In this work, we present a systematic evaluation of ViT, CLIP, DINOv2, and DINOv3 across a range of mental-rotation tasks, from simple block structures similar to those used by Shepard and Metzler to study human cognition, to more complex block figures, three types of text, and photo-realistic objects. By probing model representations layer by layer, we examine where and how these networks succeed. We find that i) self-supervised ViTs capture geometric structure better than supervised ViTs; ii) intermediate layers perform better than final layers; iii) task difficulty increases with rotation complexity and occlusion, mirroring human reaction times and suggesting similar constraints in embedding space representations.
July
- Nat Commun
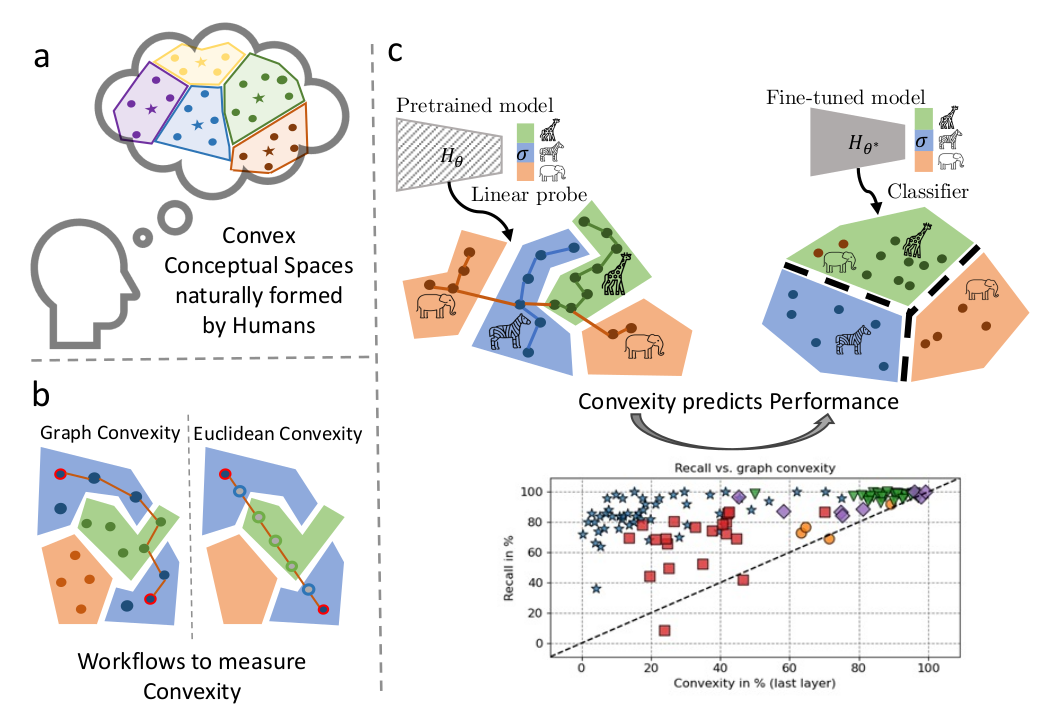 On convex decision regions in deep network representationsLenka Tětková, Thea Brüsch, Teresa Dorszewski, Fabian Martin Mager, Rasmus Ørtoft Aagaard, Jonathan Foldager, Tommy Sonne Alstrøm, and Lars Kai HansenNature Communications. Also presented at ICLR 2024 Workshop on Representational Alignment (Re-Align) , Jul 2025
On convex decision regions in deep network representationsLenka Tětková, Thea Brüsch, Teresa Dorszewski, Fabian Martin Mager, Rasmus Ørtoft Aagaard, Jonathan Foldager, Tommy Sonne Alstrøm, and Lars Kai HansenNature Communications. Also presented at ICLR 2024 Workshop on Representational Alignment (Re-Align) , Jul 2025Current work on human-machine alignment aims at understanding machine-learned latent spaces and their relations to human representations. We study the convexity of concept regions in machine-learned latent spaces, inspired by Gärdenfors’ conceptual spaces. In cognitive science, convexity is found to support generalization, few-shot learning, and interpersonal alignment. We develop tools to measure convexity in sampled data and evaluate it across layers of state-of-the-art deep networks. We show that convexity is robust to relevant latent space transformations and, hence, meaningful as a quality of machine-learned latent spaces. We find pervasive approximate convexity across domains, including image, text, audio, human activity, and medical data. Fine-tuning generally increases convexity, and the level of convexity of class label regions in pretrained models predicts subsequent fine-tuning performance. Our framework allows investigation of layered latent representations and offers new insights into learning mechanisms, human-machine alignment, and potential improvements in model generalization.
- xAI 2025
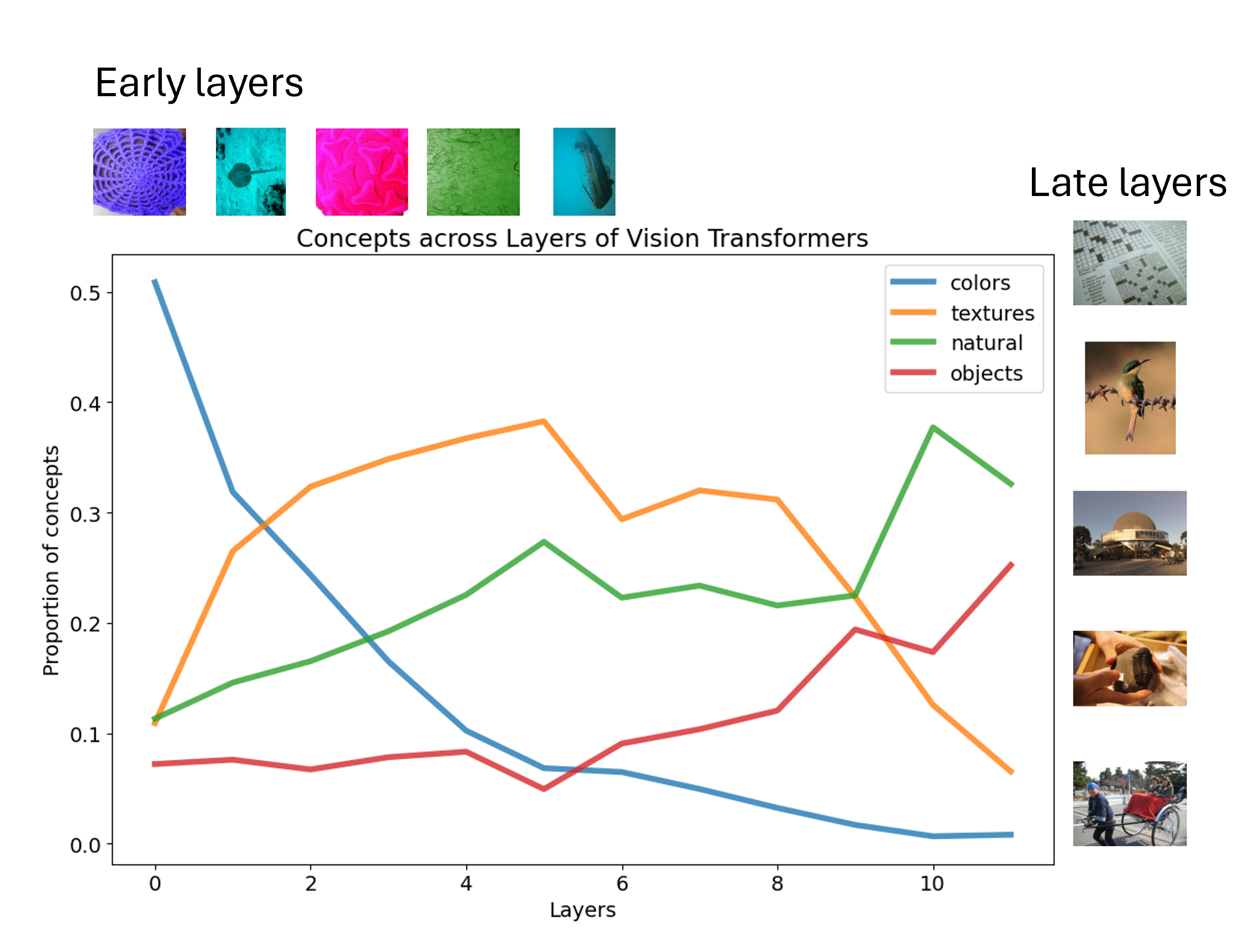 From Colors to Classes: Emergence of Concepts in Vision TransformersTeresa Dorszewski, Lenka Tětková, Robert Jenssen, Lars Kai Hansen, and Kristoffer Knutsen WickstrømIn World Conference on Explainable Artificial Intelligence. Won the best poster award at Danish Digitalization, Data Science and AI 3.0 (D3A 2025). , Jul 2025
From Colors to Classes: Emergence of Concepts in Vision TransformersTeresa Dorszewski, Lenka Tětková, Robert Jenssen, Lars Kai Hansen, and Kristoffer Knutsen WickstrømIn World Conference on Explainable Artificial Intelligence. Won the best poster award at Danish Digitalization, Data Science and AI 3.0 (D3A 2025). , Jul 2025Vision Transformers (ViTs) are increasingly utilized in various computer vision tasks due to their powerful representation capabilities. However, it remains understudied how ViTs process information layer by layer. Numerous studies have shown that convolutional neural networks (CNNs) extract features of increasing complexity throughout their layers, which is crucial for tasks like domain adaptation and transfer learning. ViTs, lacking the same inductive biases as CNNs, can potentially learn global dependencies from the first layers due to their attention mechanisms. Given the increasing importance of ViTs in computer vision, there is a need to improve the layer-wise understanding of ViTs. In this work, we present a novel, layer-wise analysis of concepts encoded in state-of-the-art ViTs using neuron labeling. Our findings reveal that ViTs encode concepts with increasing complexity throughout the network. Early layers primarily encode basic features such as colors and textures, while later layers represent more specific classes, including objects and animals. As the complexity of encoded concepts increases, the number of concepts represented in each layer also rises, reflecting a more diverse and specific set of features. Additionally, different pretraining strategies influence the quantity and category of encoded concepts, with finetuning to specific downstream tasks generally reducing the number of encoded concepts and shifting the concepts to more relevant categories.
April
- ICASSP 2025
 How Redundant Is the Transformer Stack in Speech Representation Models?Teresa Dorszewski, Albert Kjøller Jacobsen, Lenka Tětková, and Lars Kai HansenIn ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Also presented at 4th NeurIPS Efficient Natural Language and Speech Processing Workshop (ENLSP-IV 2024) – Runner up for the best short paper award at the workshop , Apr 2025
How Redundant Is the Transformer Stack in Speech Representation Models?Teresa Dorszewski, Albert Kjøller Jacobsen, Lenka Tětková, and Lars Kai HansenIn ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Also presented at 4th NeurIPS Efficient Natural Language and Speech Processing Workshop (ENLSP-IV 2024) – Runner up for the best short paper award at the workshop , Apr 2025Self-supervised speech representation models, particularly those leveraging transformer architectures, have demonstrated remarkable performance across various tasks such as speech recognition, speaker identification, and emotion detection. Recent studies on transformer models revealed high redundancy between layers and the potential for significant pruning, which we will investigate here for transformer-based speech representation models. We perform a detailed analysis of layer similarity in speech representation models using three similarity metrics: cosine similarity, centered kernel alignment, and mutual nearest-neighbor alignment. Our findings reveal a block-like structure of high similarity, suggesting two main processing steps and significant redundancy of layers. We demonstrate the effectiveness of pruning transformer-based speech representation models without the need for post-training, achieving up to 40% reduction in transformer layers while maintaining over 95% of the model’s predictive capacity. Furthermore, we employ a knowledge distillation method to substitute the entire transformer stack with mimicking layers, reducing the network size by 95-98% and the inference time by up to 94%. This substantial decrease in computational load occurs without considerable performance loss, suggesting that the transformer stack is almost completely redundant for downstream applications of speech representation models.
- Re-Align @ ICLR 2025
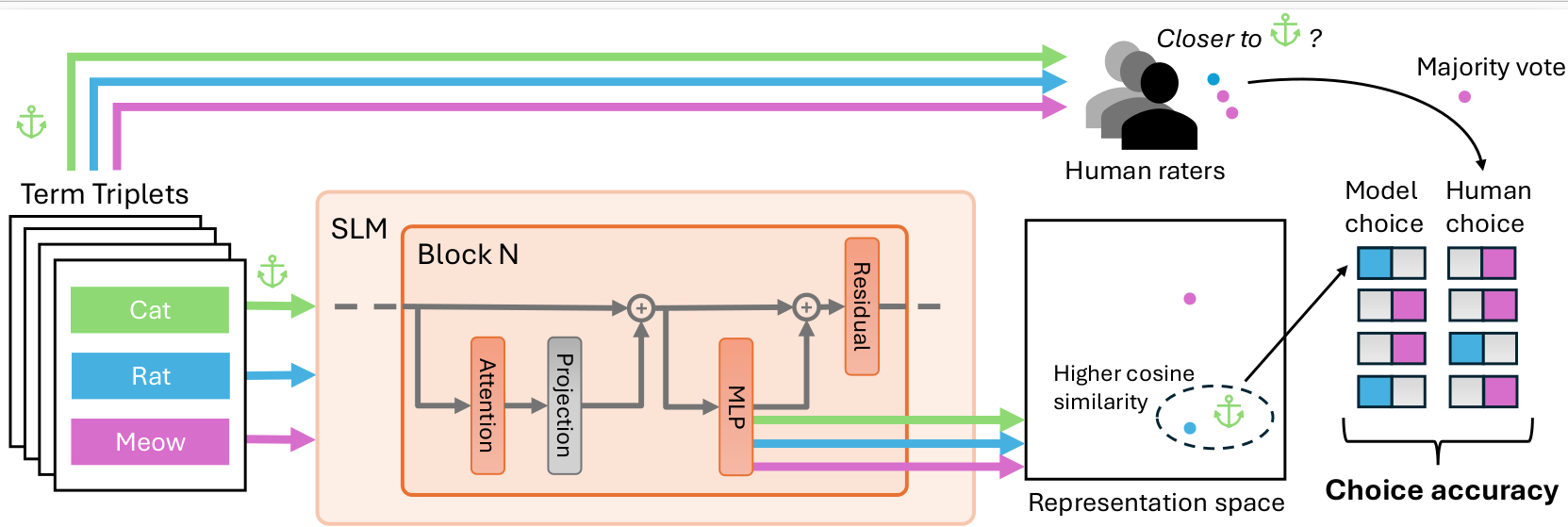 Cat, Rat, Meow: On the Alignment of Language Model and Human Term-Similarity JudgmentsLorenz Linhardt, Tom Neuhäuser, Lenka Tětková, and Oliver EberleIn Second Workshop on Representational Alignment at ICLR 2025, Apr 2025
Cat, Rat, Meow: On the Alignment of Language Model and Human Term-Similarity JudgmentsLorenz Linhardt, Tom Neuhäuser, Lenka Tětková, and Oliver EberleIn Second Workshop on Representational Alignment at ICLR 2025, Apr 2025Small and mid-sized generative language models have gained increasing attention. Their size and availability make them amenable to be analyzed at a behavioral as well as a representational level, allowing investigations of how these levels interact. We evaluate 32 publicly available language models for their representational and behavioral alignment with human similarity judgments on a word triplet task. This provides a novel evaluation setting to probe semantic associations in language beyond common pairwise comparisons. We find that (1) even the representations of small language models can achieve human-level alignment, (2) instruction-tuned model variants can exhibit substantially increased agreement, (3) the pattern of alignment across layers is highly model dependent, and (4) alignment based on models’ behavioral responses is highly dependent on model size, matching their representational alignment only for the largest evaluated models.
January
- NLDL 2025
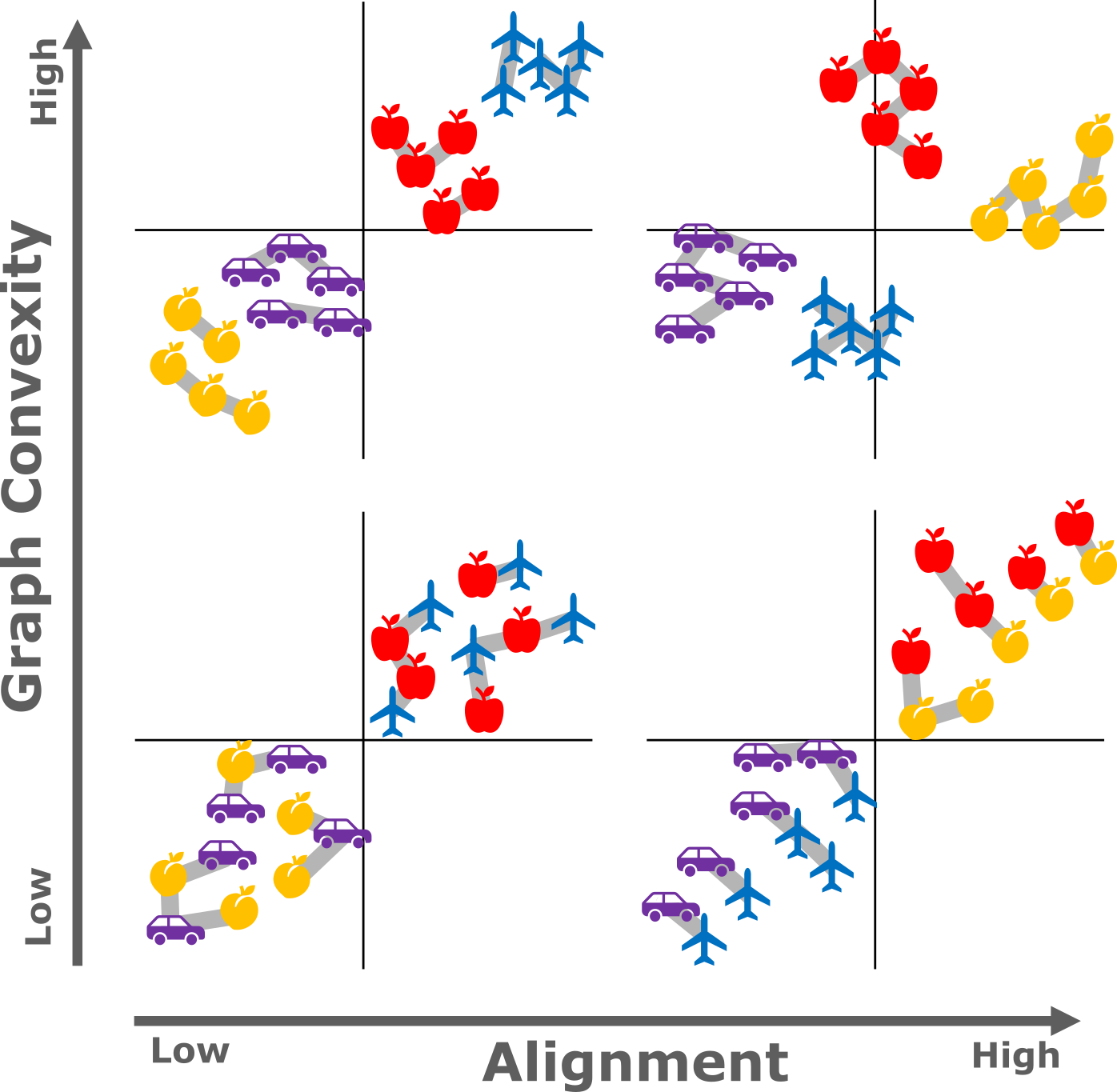 Connecting Concept Convexity and Human-Machine Alignment in Deep Neural NetworksTeresa Dorszewski, Lenka Tětková, Lorenz Linhardt, and Lars Kai HansenProceedings of the 6th Northern Lights Deep Learning Conference (NLDL), Jan 2025
Connecting Concept Convexity and Human-Machine Alignment in Deep Neural NetworksTeresa Dorszewski, Lenka Tětková, Lorenz Linhardt, and Lars Kai HansenProceedings of the 6th Northern Lights Deep Learning Conference (NLDL), Jan 2025Understanding how neural networks align with human cognitive processes is a crucial step toward developing more interpretable and reliable AI systems. Motivated by theories of human cognition, this study examines the relationship between convexity in neural network representations and human-machine alignment based on behavioral data. We identify a correlation between these two dimensions in pretrained and fine-tuned vision transformer models. Our findings suggest that the convex regions formed in latent spaces of neural networks to some extent align with human-defined categories and reflect the similarity relations humans use in cognitive tasks. While optimizing for alignment generally enhances convexity, increasing convexity through fine-tuning yields inconsistent effects on alignment, which suggests a complex relationship between the two. This study presents a first step toward understanding the relationship between the convexity of latent representations and human-machine alignment.
2024
October
-
 From Grain to Insight: Explainability in AI for Biological Data AnalysisLenka TětkováDoctoral thesis , Oct 2024
From Grain to Insight: Explainability in AI for Biological Data AnalysisLenka TětkováDoctoral thesis , Oct 2024In the field of machine learning, a common focus is on benchmark datasets, which are standardized sets of data used to compare the performance of different methods. However, this thesis emphasizes the importance of considering real-world applications, specifically, the detection of diseases and damages in grain kernels using image data. This application presents unique challenges due to the biological variation inherent in the data, which differs significantly from standard benchmark datasets. The primary objective of this research is to enhance disease detection capabilities and incorporate explainability into the process, making it more transparent and understandable. To achieve this, we investigate the use of knowledge graphs, a tool that can leverage existing metadata to improve image classification and generate specific data collections. One of the key challenges we address is the application of post-hoc explainability methods to data with biological variation. We propose a workflow to guide the selection of the most appropriate method for any given application. Furthermore, we assess the resilience of these methods to minor, naturally occurring variations in input images. Lastly, we explore concept-based explainability and alignment of representations in machine learning models. We aim to make these models more understandable by relating their operations to high-level concepts. We also strive to align the model’s perception and processing of information with human cognitive processes. This exploration could provide valuable insights into how machine learning models can be more effectively aligned with human understanding.
September
- IEEE MLSP 2024
 Convexity Based Pruning of Speech Representation ModelsTeresa Dorszewski, Lenka Tětková, and Lars Kai HansenIn 2024 IEEE 34th International Workshop on Machine Learning for Signal Processing (MLSP), Sep 2024
Convexity Based Pruning of Speech Representation ModelsTeresa Dorszewski, Lenka Tětková, and Lars Kai HansenIn 2024 IEEE 34th International Workshop on Machine Learning for Signal Processing (MLSP), Sep 2024Speech representation models based on the transformer architecture and trained by self-supervised learning have shown great promise for solving tasks such as speech and speaker recognition, keyword spotting, emotion detection, and more. Typically, it is found that larger models lead to better performance. However, the significant computational effort involved in such large transformer systems is a challenge for embedded and real-world applications. Recent work has shown that there is significant redundancy in the transformer models for NLP and massive layer pruning is feasible (Sajjad et al., 2023). Here, we investigate layer pruning in audio models. We base the pruning decision on a convexity criterion. Convexity of classification regions has recently been proposed as an indicator of subsequent fine-tuning performance in a range of application domains, including NLP and audio. In empirical investigations, we find a massive reduction in the computational effort with no loss of performance or even improvements in certain cases
July
- xAI 2024
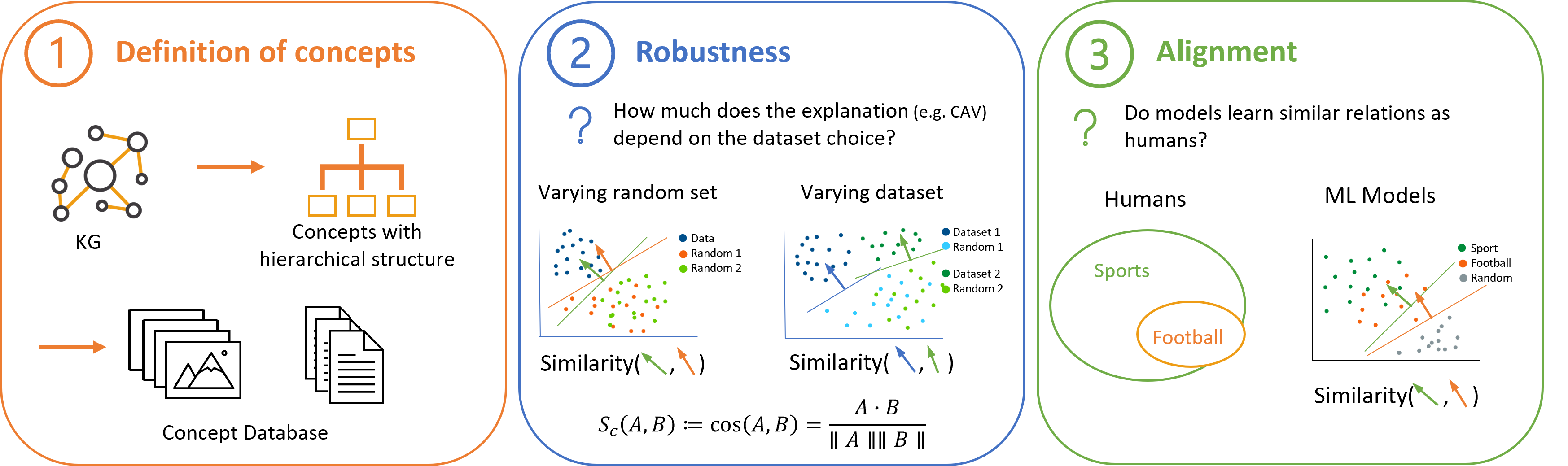 Knowledge graphs for empirical concept retrievalLenka Tětková, Teresa Karen Scheidt, Maria Mandrup Fogh, Ellen Marie Gaunby Jørgensen, Finn Årup Nielsen, and Lars Kai HansenIn World Conference on Explainable Artificial Intelligence, Jul 2024
Knowledge graphs for empirical concept retrievalLenka Tětková, Teresa Karen Scheidt, Maria Mandrup Fogh, Ellen Marie Gaunby Jørgensen, Finn Årup Nielsen, and Lars Kai HansenIn World Conference on Explainable Artificial Intelligence, Jul 2024Concept-based explainable AI is promising as a tool to improve the understanding of complex models at the premises of a given user, viz. as a tool for personalized explainability. An important class of concept-based explainability methods is constructed with empirically defined concepts, indirectly defined through a set of positive and negative examples, as in the TCAV approach (Kim et al., 2018). While it is appealing to the user to avoid formal definitions of concepts and their operationalization, it can be challenging to establish relevant concept datasets. Here, we address this challenge using general knowledge graphs (such as, e.g., Wikidata or WordNet) for comprehensive concept definition and present a workflow for user-driven data collection in both text and image domains. The concepts derived from knowledge graphs are defined interactively, providing an opportunity for personalization and ensuring that the concepts reflect the user’s intentions. We test the retrieved concept datasets on two concept-based explainability methods, namely concept activation vectors (CAVs) and concept activation regions (CARs) (Crabbe and van der Schaar, 2022). We show that CAVs and CARs based on these empirical concept datasets provide robust and accurate explanations. Importantly, we also find good alignment between the models’ representations of concepts and the structure of knowledge graphs, i.e., human representations. This supports our conclusion that knowledge graph-based concepts are relevant for XAI.
-
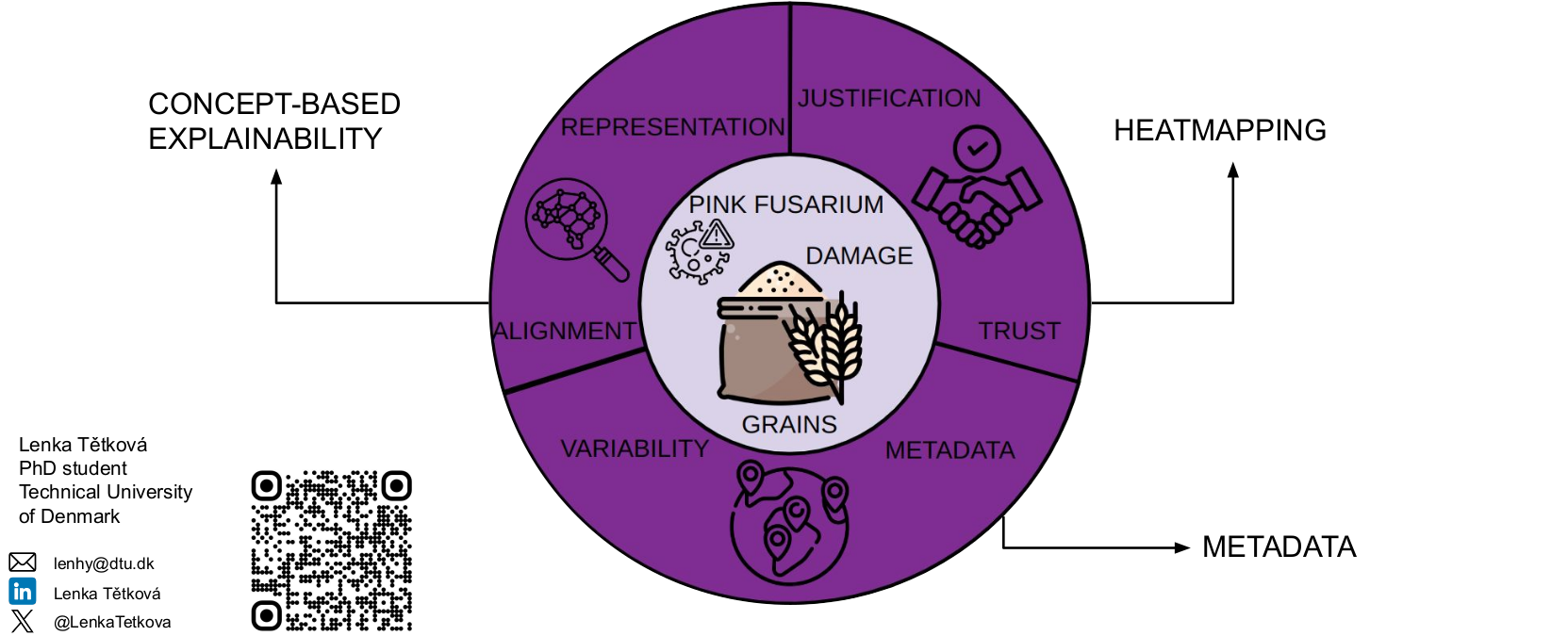 Knowledge Graphs and Explanations for Improving Detection of Diseases in Images of GrainsLenka TětkováIn xAI-2024 Late-breaking Work, Demos and Doctoral Consortium, Jul 2024
Knowledge Graphs and Explanations for Improving Detection of Diseases in Images of GrainsLenka TětkováIn xAI-2024 Late-breaking Work, Demos and Doctoral Consortium, Jul 2024Many research works focus on benchmark datasets and overlook the issues appearing when attempting to use the methods in real-world applications. The application used in this work is the detection of diseases and damages in grain kernels from images. This dataset is very different from standard benchmark datasets and poses an additional challenge of biological variation in the data. The goal is to improve disease detection and introduce explainability into the process. We explore how knowledge graphs can be used to improve image classification by using existing metadata and to create collections of data depicting a specific concept. We identify challenges one faces when applying post-hoc explainability methods on data with biological variation and propose a workflow for the choice of the most suitable method for any application. Moreover, we evaluate the robustness of these methods to naturally occurring small changes in the input images. Finally, we explore the notion of convexity in representations of neural networks and its implications for the performance of the fine-tuned models and alignment to human representations.
May
- PloS one
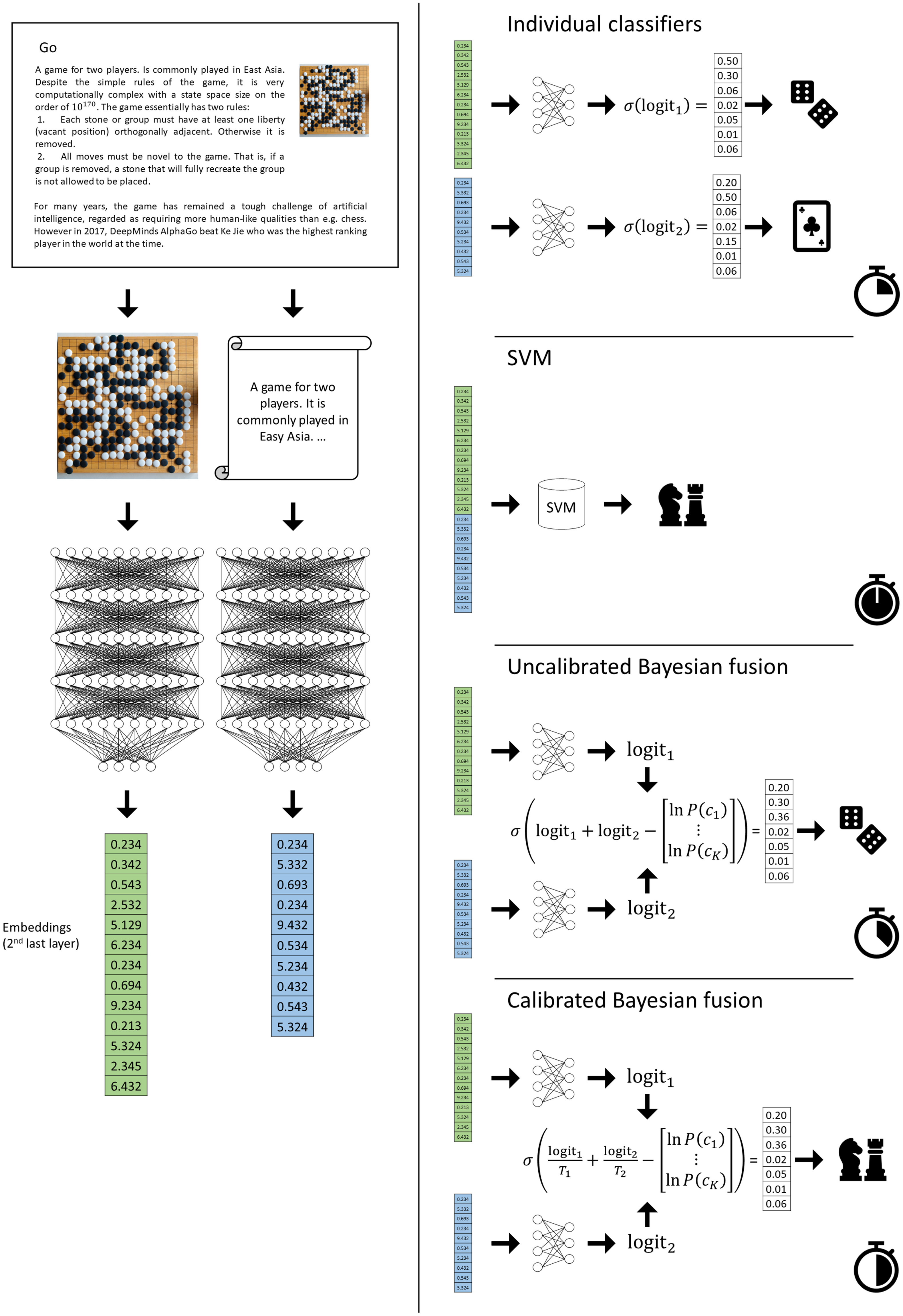 Image classification with symbolic hints using limited resourcesMikkel Godsk Jørgensen, Lenka Tětková, and Lars Kai HansenPlos one, May 2024
Image classification with symbolic hints using limited resourcesMikkel Godsk Jørgensen, Lenka Tětková, and Lars Kai HansenPlos one, May 2024Typical machine learning classification benchmark problems often ignore the full input data structures present in real-world classification problems. Here we aim to represent additional information as “hints” for classification. We show that under a specific realistic conditional independence assumption, the hint information can be included by late fusion. In two experiments involving image classification with hints taking the form of text metadata, we demonstrate the feasibility and performance of the fusion scheme. We fuse the output of pre-trained image classifiers with the output of pre-trained text models. We show that calibration of the pre-trained models is crucial for the performance of the fused model. We compare the performance of the fusion scheme with a mid-level fusion scheme based on support vector machines and find that these two methods tend to perform quite similarly, albeit the late fusion scheme has only negligible computational costs.
2023
June
- XAI4CV @ CVPR 2023
 Robustness of Visual Explanations to Common Data Augmentation MethodsLenka Tětková, and Lars Kai HansenProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Jun 2023
Robustness of Visual Explanations to Common Data Augmentation MethodsLenka Tětková, and Lars Kai HansenProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Jun 2023As the use of deep neural networks continues to grow, understanding their behaviour has become more crucial than ever. Post-hoc explainability methods are a potential solution, but their reliability is being called into question. Our research investigates the response of post-hoc visual explanations to naturally occurring transformations, often referred to as augmentations. We anticipate explanations to be invariant under certain transformations, such as changes to the colour map while responding in an equivariant manner to transformations like translation, object scaling, and rotation. We have found remarkable differences in robustness depending on the type of transformation, with some explainability methods (such as LRP composites and Guided Backprop) being more stable than others. We also explore the role of training with data augmentation. We provide evidence that explanations are typically less robust to augmentation than classification performance, regardless of whether data augmentation is used in training or not.
2021
September
- Technical reportAlquist 4.0: Towards Social Intelligence Using Generative Models and Dialogue PersonalizationJakub Konrád, Jan Pichl, Petr Marek, Petr Lorenc, Van Duy Ta, Ondřej Kobza, Lenka Hýlová, and Jan ŠedivýAlexa Prize Socialbot Grand Challenge. Winner of Alexa Prize Socialbot Grand Challenge 4 , Sep 2021
The open domain-dialogue system Alquist has a goal to conduct a coherent and engaging conversation that can be considered as one of the benchmarks of social intelligence. The fourth version of the system, developed within the Alexa Prize Socialbot Grand Challenge 4, brings two main innovations. The first addresses coherence, and the second addresses the engagingness of the conversation. For innovations regarding coherence, we propose a novel hybrid approach combining hand-designed responses and a generative model. The proposed approach utilizes hand-designed dialogues, out-of-domain detection, and a neural response generator. Hand-designed dialogues walk the user through high-quality conversational flows. The out-of-domain detection recognizes that the user diverges from the predefined flow and prevents the system from producing a scripted response that might not make sense for unexpected user input. Finally, the neural response generator generates a response based on the context of the dialogue that correctly reacts to the unexpected user input and returns the dialogue to the boundaries of hand-designed dialogues. The innovations for engagement that we propose are mostly inspired by the famous exploration-exploitation dilemma. To conduct an engaging conversation with the dialogue partners, one has to learn their preferences and interests – exploration. Moreover, to engage the partner, we have to utilize the knowledge we have already learned – exploitation. In this work, we present the principles and inner workings of individual components of the open-domain dialogue system Alquist developed within the Alexa Prize Socialbot Grand Challenge 4 and the experiments we have conducted to evaluate them.